
概要
こんにちは。株式会社アイビスのTech Blog担当です。
今回は、AIによる線画のカラー化ツールであるStyle2Paints(SEPA)を開発した、Style2Paints Researchから発表された2つの論文について紹介していきたいと思います。
紹介する論文はStyle Transfer for Anime Sketches with Enhanced Residual U-net and Auxiliary Classifier GANと、Two-stage Sketch Colorizationです。
Style2Paintsとは
Style2Paintsは、AIによる線画の自動色塗りソフトです。
GitHubからダウンロードすることができ、リポジトリには現在14kのスターが付いています。
色塗りの質が非常に高い、どのように色付けを行うかについてユーザが細かく制御できる、出力される結果が一つのjpgやpng形式の画像ではなくPSDレイヤーであるなどの特徴があります。
初期のものはLvmin Zhangさんという方が開発し、現在はStyle2Paints Researchの元でバージョン5(バージョン5でStyle2PaintsからSEPAという名前に改名される)まで開発が進んでいます。
イラストから抽出したスタイルをスケッチに適用する
まずは、2017年に発表されたStyle Transfer for Anime Sketches with Enhanced Residual U-net and Auxiliary Classifier GANという論文について簡単に紹介してきたいと思います。
Style2Paints V1に対応する論文で、図.1のように、スケッチとイラストのペアに対して、イラストからスタイルを抽出してスケッチに適用する手法を提案しています。

基本構造はGAN(Generative Adversarial Network)であり、GeneratorにU-net、DiscriminatorにAC-GANを採用しています。
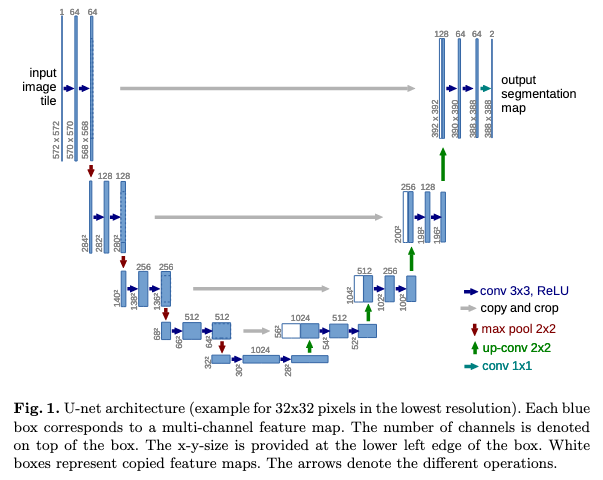
U-netは画像のセグメンテーションタスクなどでよく見られるネットワーク構造であり、図.2のようにEncoder-Decoderの構造を持ちますが、各解像度でのEncoderの出力がDecoder側にコピー、結合されます。
Encoder側の物体の位置情報などの低次元の情報と、Decoder側の抽象度の高い情報を両方利用できるという特徴があります。
今回の論文のGeneratorの構造は、図.3のようにU-netに対していくつか修正が加えられたものとなっています。
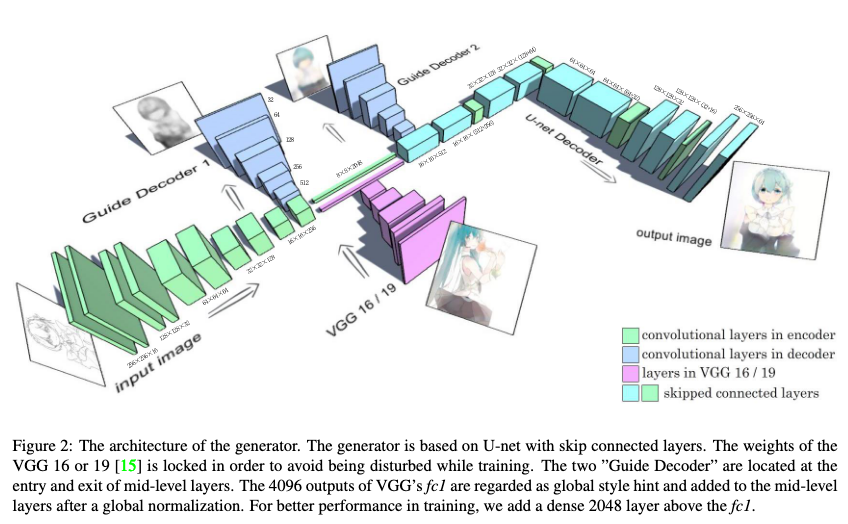
図.3のように、リファレンス画像となるイラストをVGG 16/19に入力して得られる特徴量ベクトル1x1x4096をglobal style hintとして、Encoderの出力と結合した後、Decoderに入力しています。VGG 16/19の重みは学習中、固定されています。
また、U-netの学習では、低レベルレイヤー間でのやり取りのみで問題が解決できると判明した場合は、高レベルレイヤーはわざわざ学習を行わない、つまり、損失関数の勾配が中間層に伝わりにくいということが知られています。
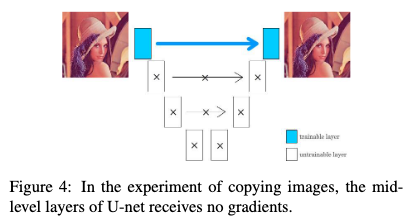
論文では、この勾配消失問題に対して、二つのGuide Decoderを使って、中間層に直接的に損失を追加するという方法で解決しようと試みています(図.3)。
2つのGuide Decoderはそれぞれ中間レイヤーの入り口と出口に配置されており、1つ目のGuide Decoderはグレースケール画像を出力するように、2つ目のGuide Decoderはイラスト画像を出力するようにトレーニングが行われます。
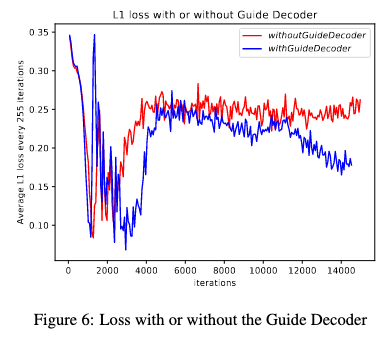
Guide Decoderがある場合とない場合での、損失関数の遷移は以下のようになります。
Guide Decoderがある場合では、イテレーション数が増加しても損失関数の改善が見られます。
最終的な損失関数は以下の通りです。
$$
\begin{eqnarray}
L_{l_1}(V, G_{f, g_1, g_2}) = E_{x,y \sim P_{data}(x,y)}[||y-G_f(x, V(y))||_1 \\
+ \alpha||T(y)-G_{g_1}(x)||_1 + \beta||y-G_{g_2}(x, V(y))||_1]
\end{eqnarray}
$$
$x$と$y$はペア付けされたスケッチとイラスト、$V(y)$はVGG 19、$G_f(x, V(y))$はU-net、$G_{g_1}(x)$は1つ目のGuide Decoder、$G_{g_2}(x, V(y))$は2つ目のGuide Decoder、$T(y)$は$y$をグレースケール画像に変換する関数です。論文では$\alpha$と$\beta$はそれぞれ、0.3と0.9に設定されていました。
なお、論文中の損失関数の定義式では、VGG 19に対応する関数$V(x)$はスケッチ$x$を引数として受け取っていたのですが、論文中の説明からVGG 19に入力される画像はイラスト$y$であると考えられるため、上式ではそのように変更しています。
続いてDiscriminatorです。DiscriminatorはAC-GANを採用しています。
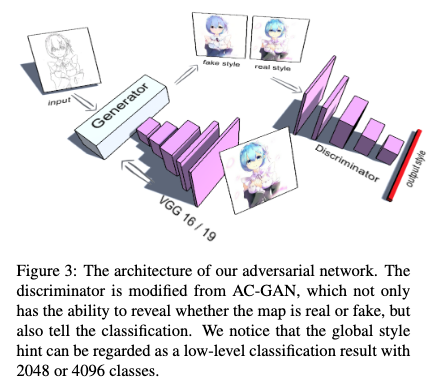
一般的なGANのDiscriminatorは、入力された画像が本物か偽物かのみを判別しますが、AC-GANは本物か偽物の判別と同時に、通常の画像分類タスクのような多クラス分類を行います。
今回は、イラスト画像をVGG 19に入力して得られたglobal style hintを画像のクラスラベルと見なします。
Discriminatorの出力は4096次元のベクトルであり、入力された画像が本物であった場合、global style hintと同じになるように、偽物であった場合は、全ての値が0になるようにトレーニングが行われます。
以下は、今回の手法を用いて得られた画像一覧です。

ユーザが制御可能なスケッチの半自動色塗りシステム
次に、2018年に発表されたTwo-stage Sketch Colorizationについて紹介していきます。
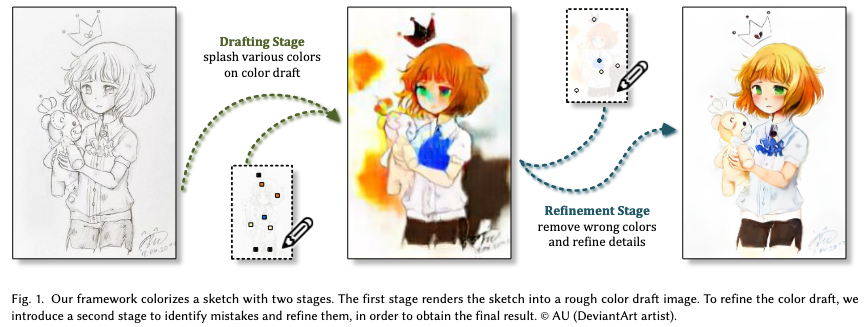
こちらは、前出のイラスト画像からスタイルを抽出してスケッチに適用するというタスクとは異なり、ユーザが色を指定するとそれに従って自動で色塗りを行うというタスクに取り組んでいます。
この論文の主なアイデアは、色を塗るというタスクを、色の構成を決める下書きステージと、色の間違いを修正する改善ステージという2つのサブタスクに分けるというものです。
下書きステージでは、色の構成を決定しますが、その際に、なるべく使われる色のバラエティが豊富になるようにします。画像内に色の間違いや、ぼやけたテクスチャが存在しますが、ユーザのヒントに従って可能な限り鮮やかな色塗りを実現しようとします。
改善ステージでは、下書きステージで得られた画像の問題のある色の領域を発見し改善します。さらに、新たなユーザからのヒントのセットを読み取り、新たな色の導入及び、間違った色の修正を行います。
色塗りという複雑な作業を、比較的シンプルで明確な目標をもった2つのステージに分割することによって、モデルの学習を効果的に行うことができます。
また、2つのステージのそれぞれのモデルの学習は完全に独立して行われます。
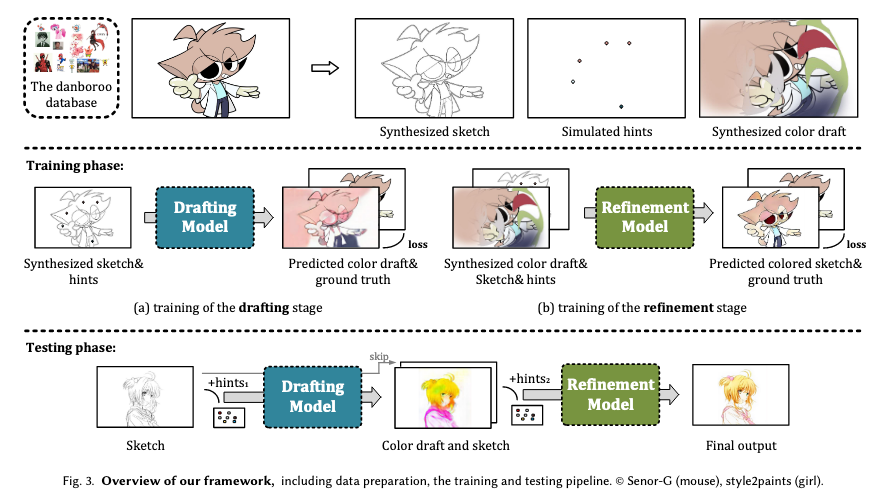
それでは、以下、モデルの構造や学習方法、データセットの作成方法について詳しく解説していきます。
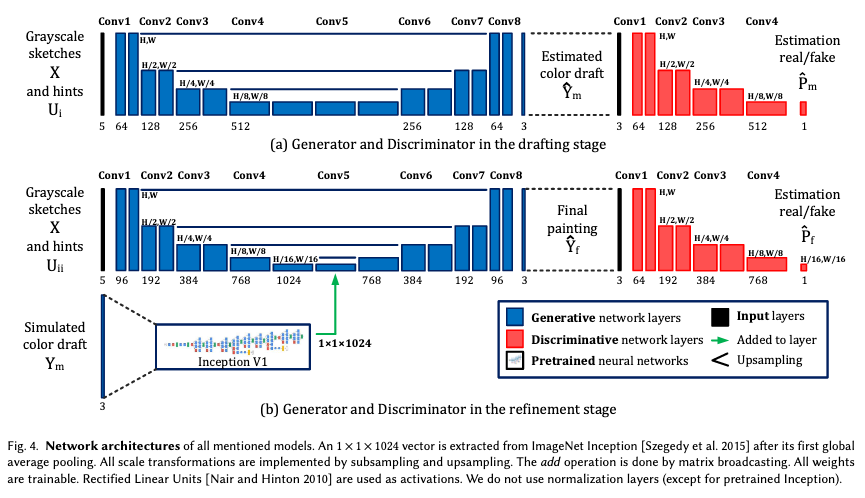
下書きステージのGeneratorとDiscriminatorの構造は図.10aのようになります。
GeneratorはU-netを採用しており、入力データはスケッチ画像とユーザのヒントです。
入力データのチャンネル数が5となっているのですが、ユーザのヒントにRBGではなく、RBGA画像を用いているため、スケッチ画像(1チャンネル) + ユーザのヒント(4チャンネル) = 入力データ(5チャンネル)となっているのだと思われます。
下書きステージのモデルの最適化は以下の式に従います。
$$
\begin{eqnarray}
\arg \min_{G} \max_{D} E_{x, u_i, y_f \sim P_{data(x, u_i, y_f)}}[||y_f-G(x, u_i)||_1\\
+ \alpha L(G(x, u_i)) – \lambda log(D(y_f)) – \lambda log(1-D(G(x,u_i)))]
\end{eqnarray}
$$
$x$はスケッチ、$u_i$はユーザのヒント、$y_f$はイラストです。$L(x)$は下書きの色の豊富さを高める正規化項で、以下のように定義されています。
$$
L(x) = – \sum^3_{c=1}\frac{1}{m}\sum^m_{i=1}(x_{c,i}-\frac{1}{m}\sum^m_{i=1}x_{c,i})^2
$$
$x_{c,i}$は$c$番目のチャンネルの$i$番目の要素、mは画像の幅×高さです。
このように、$L(x)$は各チャンネル空間での分散を大きくする働きがあります。
次に改善ステージのGeneratorとDiscriminatorの構造について解説していきます(図.10b)。
基本的な構造や入力データは下書きステージと同じですが、シミュレーションされた色の下書き画像をInception V1に入力して得られる特徴量ベクトルを、中間レイヤーにて結合している点が異なります。
ここで、シミュレーションされた色の下書き画像について詳しく説明していきたいと思います。
改善ステージの目的は、下書きステージで得られた色の下書きの問題のある色の領域を発見し改善することです。
従って、学習には、ペア付けされた色の下書きと最終的なイラストのデータセットが必要となります。
このデータセットを作成する方法の一つとして、下書きステージのモデルの学習を十分に行なった後、そのモデルを用いて作成するという方法が考えられます。
しかし、この方法では、改善ステージのモデルが、下書きステージのモデルが生成する特定のタイプの色の下書きについて過学習を起こしてしまい、汎化能力が低下してしまう可能性があります。
また、今回は意図的に色塗りタスクを個別の目的の方法を持った2つのステージに分割しているため、本質的に1つのモデルを学習させるような方法は選択肢として考えないというスタンスをとっています。
そこで、論文では色の下書きと最終的なイラストのデータセットを生成する方法として以下のようなものを採用しています。
まず、下書きステージが生成する色の下書きを観察すると、以下のようなノイズが確認されます。
- 色の間違い
青い太陽、緑の人間の顔など、誤って塗りつぶされた色。 - 色のにじみ
周囲の、しかし無関係な領域への色の漏れ。例えば、肌の色が背景に漏れるなど。 - ぼやけと歪み
彩度が低く水彩でぼやけているか、領域が過度にテクスチャ化されているか、いくつかの構造線が歪んでいる。
論文ではこれらのノイズが含まれる画像を人工的な画像処理によってシミュレーションし、色の下書きと最終的なイラストのデータセットを作成しています。
シミュレーションに使われる画像処理は以下の通りです。
- Random Region Proposal and Pasting:色の間違いをシミュレーションする。
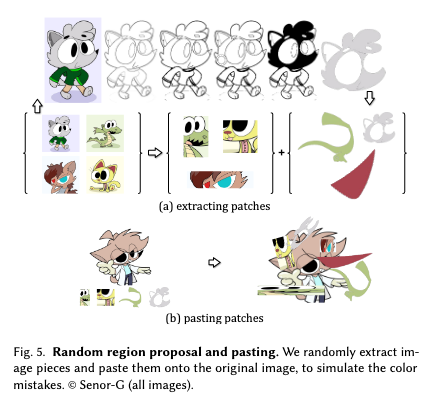
図.11 出典:Lvmin Zhang, Chengze Li, Tien-Tsin Wong, Yi Ji, Chunping Liu. Two-stage Sketch Colorization
以下の2つの方法を用いて画像から10,000個のパッチを抽出し、パッチをランダムに貼り付けることで色の下書きを作成する。
1つ目の方法では、カラー画像を64×64から256×256のサイズでランダムにcropする。
2つ目の方法では、以下の領域提案法を使用して不規則な形状のパッチを取得する。 ガウスフィルターがかけられたぼかし画像と元画像の差を計算し、結果をクリップし、2値化することで、シャープなエッジマップを取得し、trapped-ball segmentationによって、不規則な形状のピースを抽出するためのカラーマスクを得る。 - Random Transform:ぼやけと歪みをシミュレーションする。

図.12 出典:Lvmin Zhang, Chengze Li, Tien-Tsin Wong, Yi Ji, Chunping Liu. Two-stage Sketch Colorization
ランダムな2×3行列を作成し、Spatial Transform Layer(STL)を用いて画像を変換。
この変換によって局所的パターンをぼやかし、同時に全体的なノイズを追加する。 - Random Color Spray:色のにじみをシミュレーションする。

図.13 出典:Lvmin Zhang, Chengze Li, Tien-Tsin Wong, Yi Ji, Chunping Liu. Two-stage Sketch Colorization
画像からランダムに色が選択される。
選択された色をいくつかの直線のパスに対してランダムな幅でスプレーする。
改善ステージのモデルの最適化は以下の式に従います。
$$
\begin{eqnarray}
\arg \min_{G} \max_{D} E_{x,u_{ii}, y_m, y_f \sim P_{data}(x,u_{ii},y_m,y_f)}
[ – \lambda log(D(y_f)) \\
– \lambda log(1 – D(G(x, u_{ii}, y_m))) + ||y_f – G(x, u_{ii}, y_m)||_1]
\end{eqnarray}
$$
$x$はスケッチ、$u_{ii}$はユーザのヒント、$y_m$は合成された色の下書き、$y_f$はイラストです。
最後に、今回の手法と別の機械学習ベースの手法を比較した画像は以下の通りになります。
一番右側の列が今回の手法を用いて色塗りを行なった画像です。
他の手法と比較しても、色塗りの質が非常に高いことが確認できるかと思います。

まとめ
今回は、Style Transfer for Anime Sketches with Enhanced Residual U-net and Auxiliary Classifier GANとTwo-stage Sketch Colorizationというスケッチの自動色塗りに関連した論文を2つ紹介しました。
どちらも、U-netベースのGeneratorを用い、中間レイヤーで画像に適用するスタイルに相当する特徴量ベクトルを注入しているという共通点がありますが、最初の論文では、さらに2つのGuide DecoderとAC-GAN、2番目の論文では色塗りタスクを下書きステージと改善ステージに分割するという工夫が行われていました。
また、こちらのページから、Style2Paints Researchが開発してるその他のツールや、発表した論文が公開さてていますので、ご興味のある方はぜひご参照ください。
参考文献
- Lvmin Zhang, Yi Ji, Xin Lin. Style Transfer for Anime Sketches with Enhanced Residual U-net and Auxiliary Classifier GAN arxiv:1706.03319
- Lvmin Zhang, Chengze Li, Tien-Tsin Wong, Yi Ji, Chunping Liu. Two-stage Sketch Colorization
- Olaf Ronneberger, Philipp Fischer, Thomas Brox. U-Net: Convolutional Networks for Biomedical Image Segmentation arxiv:1505.04597
