
概要
こんにちは。株式会社アイビスのTech Blog担当です。
今回は、論文Training Generative Adversarial Networks with Limited Dataで発表されたStyleGAN2-ADAを使って、二次元キャラクターフェイスを生成してみました。

StyleGAN2-ADAでは、Adaptive discriminator augmentationという、Discriminatorに注入する画像に対して確率的にdata augmentationを適用する手法を用いて、少量のデータセットでもDiscriminatorの過学習やモード崩壊を防ぎ、安定した学習を可能にしています。
今回はさらに、同じデータセットを用いてAdaptive discriminator augmentationなしのStyleGAN2でもトレーニングを行い、結果を比較してみました。
StyleGANシリーズのおさらい
まずは、簡単にStyleGANシリーズのおさらいをしてみたいと思います。
StyleGAN
2018年に、A Style-Based Generator Architecture for Generative Adversarial Networksという論文で発表されたモデルです。
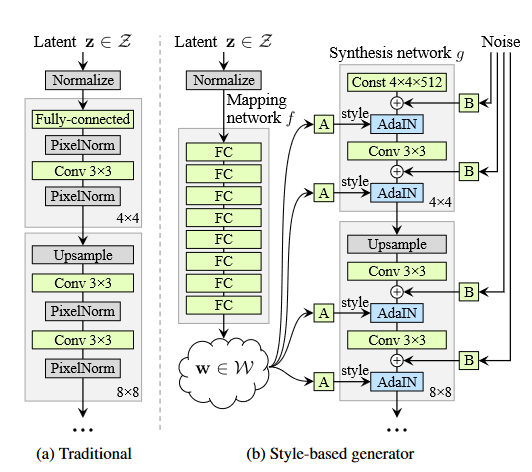
Progress GANの流れを汲んでいますが、以下のような特徴があります。
- Mapping network
従来は生成された乱数はネットワークの最初の層のみに注入していたが、StyleGANではランダムに生成された潜在変数zをMapping Networkで潜在変数wに変換し、wから抽出した特徴量を各解像度で注入しています。 - AdaIN
各解像度で特徴量マップにstyleを適用する方法として、AdaINという手法を用いています。特徴量マップとは、ここではSynthesis networkを通過するチャンネル単位ごとの特徴量を指します。AdaINはadaptive instance normalizationの略で、各特徴量マップの平均と標準偏差を調整する役割を持ちます。 - Noise input
各解像度でノイズを注入することで、ネットワークが疑似乱数を生成する必要がなくなり、ネットワークのキャパシティが増加します。 - Mixing regularization
トレーニング中にある一定の確率で、二つの乱数から生成された潜在変数w1の前半とw2の後半をmixすることにより、各解像度でのスタイルの独立性を高めています。
StyleGAN2
2019年に、Analyzing and Improving the Image Quality of StyleGANという論文で発表されたモデルです。
元々のStyleGANでは、生成画像に下図のような水滴状の歪み(droplet-like artifact)が発生してしまう問題がありました。

こちらの論文では、まずその水滴のような歪みの原因について分析を行うことから始め、その原因がAdaINが強すぎるためではないかという仮説を立てています。AdaINはそれぞれの特徴量マップの平均と分散を別々に正規化することによって、ある特徴量マップが他の特徴量マップに対してどれくらいの強度を持つかという、相対的な強度情報を強制的に破壊してしまっています。従って、Generatorはインスタンス正規化を通過する信号強度情報を局所的なスパイクとして忍ばせようとします。これが、水滴状の歪みの原因となっているのではないかと主張しています。
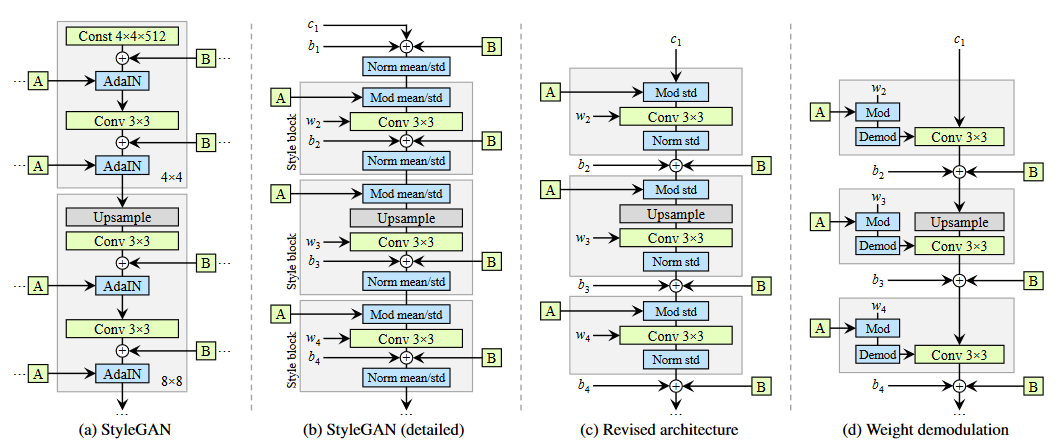
StyleGAN2では、各解像度でstyleを適用する方法を以下のように修正しています。
まず、スタイル変調(図.3bでMod mean/stdと表記されている部分)と特徴量マップの正規化(図.3bでNorm mean/stdと表記されている部分)では、標準偏差の調整のみを行い、平均の調整は行いません(図.3c)。
また、各特徴量マップにスタイル変調を適用した後に畳み込みを行う処理は、畳み込み層の重みのスケールを変えることと等価なので、代わりに下式のように畳み込み層の重みの調節を行います(図.3dでModと表記されている部分)。
$$
w’_{ijk} = s_i \cdot w_{ijk}
$$
$w’_{ijk}$は変調が適用された重み、$w_{ijk}$は元々の畳み込み層の重み、$s_i$は入力される特徴量マップのi番目のスケールです。indexの$i$は入力される特徴量マップの番号、$j$は出力される特徴量マップの番号、$k$は空間的な場所に対応しています。
さらに、下式のように特徴量マップの正規化も畳み込み処理に組み込みこんでいます(図.3dでDemodと表記されている部分)。
$$
w^{”}_{ijk} = \frac{w’_{ijk}}{\sqrt{\sum_{i,k}{w’_{ijk}}^2 + \epsilon}}
$$
最終的なGeneratorの構造は、図.3dのようになります。
StyleGAN2では、他にも以下に挙げる修正を行っています。
- progress growingは廃止し、代わりにGeneratorにはskip connection、Discriminatorにはresidual netを採用しています。
- 生成される画像の質とPPL (perceptual path length)は強い相関があるため、PPLを小さくするpath length regularizationという正規化項を新しく導入しています。PPLは潜在空間w上での生成画像の滑らかさを測る指標です。
- 生成される画像の高解像度でのネットワークの寄与が小さかったので、高解像度に対応するレイヤーを増やしています。
StyleGAN2-ADA
2020年に、Training Generative Adversarial Networks with Limited Dataという論文で発表されたモデルです。
こちらは、前出の2つのような新しいGANネットワークの構造の提案という内容とは異なり、画像認識や物体検出、セグメンテーションタスクでは一般的なdata augmentationをGANでも使えるようにしたという内容の論文です。
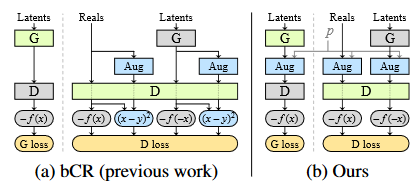
GANのトレーニングにdata augmentationを適用する場合、他の画像認識タスクなどでは見られない問題が発生します。GANのトレーニングでは、基本的にDiscriminatorはトレーニングデータセットの確率分布を学習し、GeneratorはDiscriminatorの導きによって、自身が生成する画像の確率分布がトレーニングデータセットの確率分布に収束するように学習を進めます。しかし、Discriminatorに見せる画像に対してdata augmentationを行うと、Discriminatorが学習する確率分布が変化し、結果としてGeneratorはdata augmentationが適用された画像を生成するようになってしまいます。この状態を、data augmentationがleakしたなどと表現します。GANのトレーニングにdata augmentationを適用する場合は、augmentationがleakするのを防ぐ必要があります。
Improved Consistency Regularization for GANsという論文では、bCR (balanced consistency regularization)という手法を用いてこの問題に対処しようと試みています(図.5a)。bCRでは、Discriminatorの学習時に、data augmentationを適用した画像とそうでない画像の出力が同じになるような正規化項を加えて、Discriminatorの汎化を試みています。しかし、bCRではGeneratorがaugmentationがleakした画像を生成しても明示的にpenaltyが課されないため、実際はaugmentationのleakを防げていないとStyleGAN2-ADAの論文では主張されています。
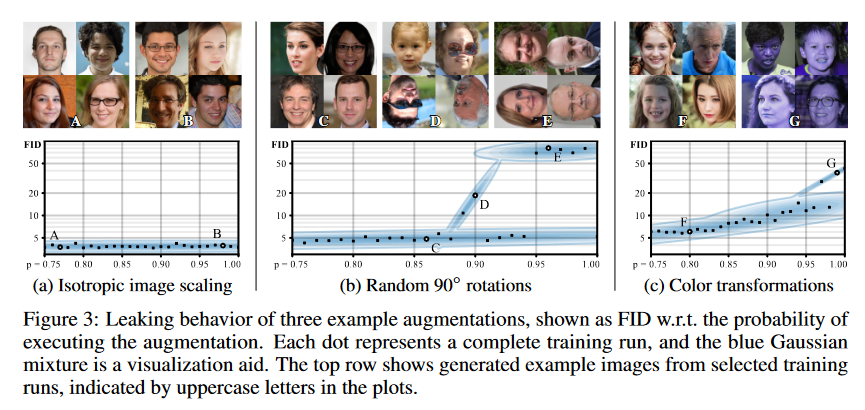
StyleGAN2-ADAではまず、bCRを適用しなくてもDiscriminatorに注入する画像にdata augmentationを適用する確率が十分小さければ、augmentationがleakしないということを実験的に確認しています。図.6では、3つのdata augmentationの手法に対して、異なる適用確率pで学習を行った場合、FIDがどのように変化するかをまとめたものです。手法によってleakしやすさの違いがあるものの、全てのaugmentation手法についてpが十分小さければFIDが増加しないことが確認できるかと思います。
そこで、StyleGAN2-ADAでは、data augmentationを適用する確率や強さを表すパラメータpを0から始め、Discriminatorが過学習を起こしていないか常に監視し、過学習の兆候が確認されるとpを少し増加させるという方法を用いて、data augmentationのleakとDiscriminatorの過学習を同時に防いでいます。この手法を、Adaptive discriminator augmentationと呼びます。
イメージとしては、Generatorがaugmentationを適用した画像を生成する方向に学習が進むことは無いが、たまたまGeneratorがaugmentationを適用した画像を生成してしまったとしてもそれに明示的にペナルティが課されることは無いため、偶然そういった現象が発生しないように注意深くpを調節するといった仕組みであると考えています。
また、ここでは詳細な紹介は省略させて頂きますが、StyleGAN2-ADAの次のモデルに相当するStyleGAN3もすでに発表されており、StyleGAN3では歯の位置や髪、髭の模様が不自然に絶対座標系に固定されてしまう問題を解消しています。詳しくはこちらの論文をご参照ください。
Alias-Free Generative Adversarial Networks
データセット
ということで、今回はdanbooru datasetを使って、ffhqデータセットで事前学習したStyleGAN2-ADAとStyleGAN2(正確にはSytleGAN2-ADAのリファレンス実装においてdata augmentationを無効化したもの)に転移学習を適用してみたいと思います。danbooru datasetはgwernさんという方が作成した巨大イラスト画像データセットで、ffhqはGANのベンチマークとしてよく用いられる人の顔のデータセットです。danbooru datasetから顔の領域のみを抽出したデータセットがこちらに公開されていたので、今回はdanbooru datasetを直接用いるのではなく、こちらのデータセットを使わせて頂くことにしました。
学習環境
学習はGoogle Colaboratory上で丸3日間行いました。画像の解像度は512×512で、mapping networkのレイヤーの個数は8にしています。data augmentationに関しては、論文では18種類の変換が6個のカテゴリに分類分けされており、デフォルトではblit(x-flipやrotationなどのカテゴリ)、geom(より一般的なジオメトリ変換のカテゴリ)、color(色調の変換に関するカテゴリ)の3つが有効になっているのですが、トレーニングを行ってみたところcolorに関するaugmentationがleakしてしまっているようだったので、blitとgeomのみを有効にしました。16tickごとにfid50kのメトリクスを計測して、Discriminatorの過学習及びモード崩壊が発生していないか確認しています。
学習結果と比較
StyleGAN2とStyleGAN2-ADAの学習過程の動画は以下の通りです。
data augmentationを適用していないStyleGAN2ではモード崩壊が発生していることが分かります。
FIDやその他のメトリクスの比較は以下の通りです。
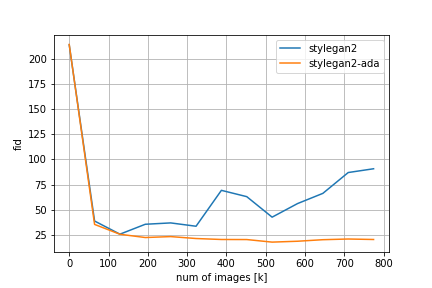
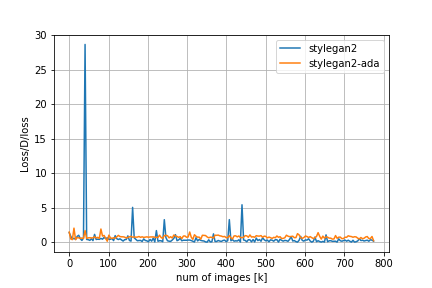
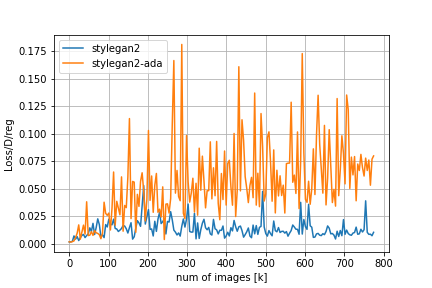
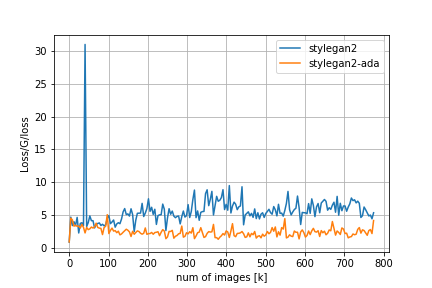
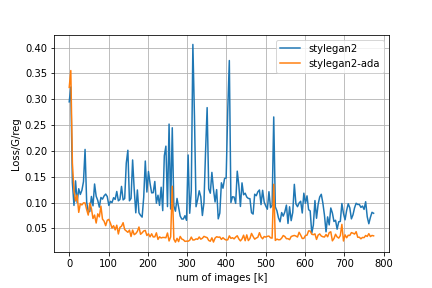
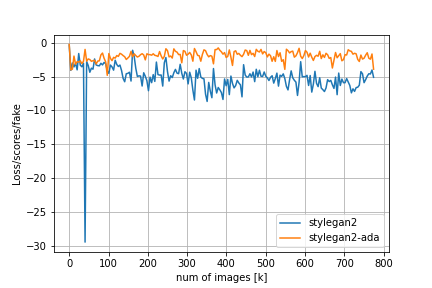
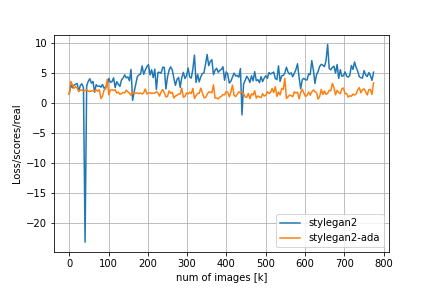
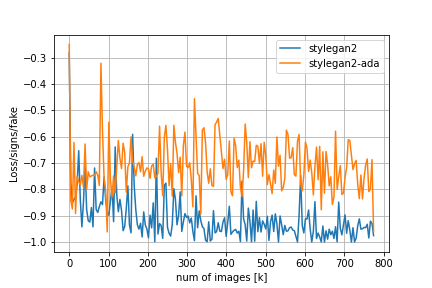
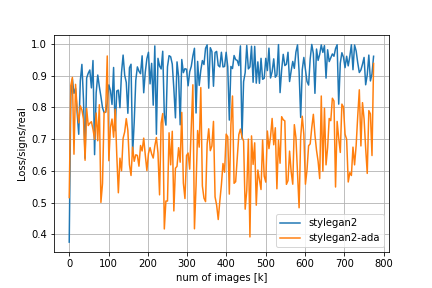
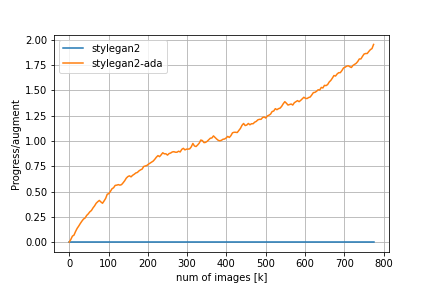
Loss/D/regはDiscriminatorについての正規化項でr1 penalty、Loss/G/regはGeneratorについての正規化項でpl penaltyに対応しています。FIDの推移を見てみると、adaなしのStyleGAN2では200kimgを超えたあたりからDiscriminatorの過学習とモード崩壊が始まってしまうのに対し、adaを適用するとトレーニングが進んでもFIDの値が低い状態を保っていることが分かります。
考察
今回の実験で得られた生成画像をいくつか観察してみると、こちらやこちらのサイトで見られるStyleGAN2の結果と比較して画像の質があまり良くない印象を受けました(この2つのサイトは同じモデルを使って画像を生成しているようです)。
以下その原因として考えられる項目を挙げていきたいと思います。
- 学習データの質の問題
イラスト画像から顔の領域のみを抽出してデータセットを作成する場合、上手く切り取られていなかったり、重複していたり、カラー画像ではなく白黒画像であったりなどの画像に対して適切な処理を施さないとデータセットの質が低下してしまいます。
今回使用したデータセットがどのような方法を用いて作成されたのか明記されていなかったため、はっきりとしたことは言えないのですが、上記に挙げたサイトで学習に使用されたデータセットと比較して質が悪かった可能性があります。 - 転移学習の問題
今回の実験では、人の顔であらかじめ学習済みのモデルに対して転移学習を行いました。転移学習を行うと学習の収束が早くなるというメリットがあるのですが、初期状態から学習させた場合と比較すると生成される画像の質が落ちてしまった可能性があります。
まとめ
今回は、StyleGAN2とStyleGAN2に対してAdaptive discriminator augmentationを適用したStyleGAN2-ADAを用いて、人の顔から二次元キャラクターフェイスへの転移学習を行い結果を比較してみました。
StyleGAN2では割と早い段階でDiscriminatorの過学習とモード崩壊が発生していたのに対し、StyleGAN2-ADAではイテレーション数が増加してもFIDが低い値のまま学習が進み、Discriminatorの過学習とモード崩壊を効果的に防ぐことに成功していました。
Adaptive discriminator augmentationは学習に用いるデータセットのサイズが小さい時に、より効果を発揮するので、今度は取得可能な画像の数が限られているような場合(特定のキャラクターの顔画像のみのデータセットなど)についても学習を行い、検証してみたいと考えています。
参考文献
- Tero Karras, Samuli Laine, Timo Aila. A Style-Based Generator Architecture for Generative Adversarial Networks arxiv:1812.04948
- Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, Timo Aila. Analyzing and Improving the Image Quality of StyleGAN arxiv:1912.04958
- Tero Karras, Miika Aittala, Janne Hellsten, Samuli Laine, Jaakko Lehtinen, Timo Aila. Training Generative Adversarial Networks with Limited Data arxiv:2006.06676
- Zhengli Zhao, Sameer Singh, Honglak Lee, Zizhao Zhang, Augustus Odena, Han Zhang. Improved Consistency Regularization for GANs arxiv:2002.04724
- Tero Karras, Miika Aittala, Samuli Laine, Erik Härkönen, Janne Hellsten, Jaakko Lehtinen, Timo Aila. Alias-Free Generative Adversarial Networks arxiv:2106.12423
- Danbooru2020: A Large-Scale Crowdsourced and Tagged Anime Illustration Dataset
- High-Resolution Anime Face Dataset (512×512) | Kaggle
- Making Anime Faces With StyleGAN
- Generating Anime Characters with StyleGAN2 | by Fathy Rashad | Towards Data Science
