
概要
こんにちは。株式会社アイビスのTech Blog担当です。
当ブログでは、今までGAN(Generative Adversarial Network:敵対的生成ネットワーク)関連の研究を取り扱った記事を投稿していたのですが、今回は少し趣向を変え、「最新のリアルタイム物体検出モデルYOLOXの紹介」と題して以下の論文について紹介していきたいと思います。
YOLOX: Exceeding YOLO Series in 2021
YOLOX
YOLOXは、2021年に論文YOLOX: Exceeding YOLO Series in 2021で提案された最新のリアルタイム物体検出モデルです。
下図の通り、リアルタイム性やモデルサイズが重視されるような状況で、YOLOv5やEfficientDetといった過去のモデルよりも、物体検出の性能を表すCOCO APにおいて高い値を示しています。
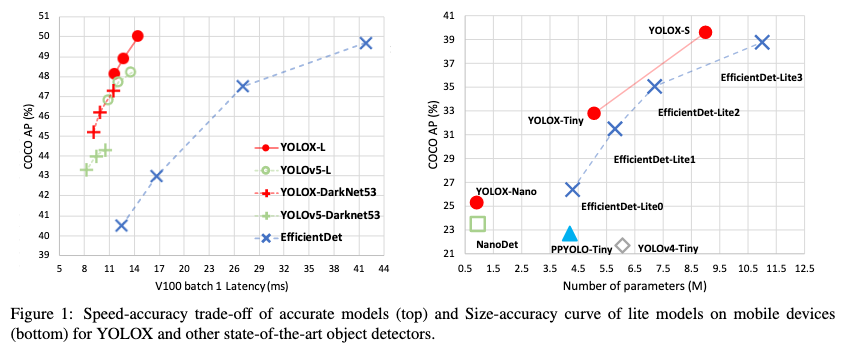
YOLOXは、YOLOシリーズの系譜を継ぐモデルですが、その命名や新規性について物議を醸している(参照)YOLOv5ではなく、YOLOv3をベースラインモデルとして、Decoupled head、OTA(Optimal Transport Assignment)、MosaicやMixUpといった物体検出の最新の手法を取り入れています。
また、論文では、トレーニング時の正解ボックスと予測ボックスの割り当てを最適輸送問題として定式化して解くOTAを簡略化した、SimOTAという新たな正解ボックスと予測ボックスの割り当て手法を提案しています。
実装
それでは、YOLOXの実装について以下で詳しく紹介していきます。
Baseline
ベースラインモデルとして、バックボーンにDarkNet53とSPP(Spatial Pyramid Pooling)層を採用したYOLOv3-SPPを用いています。
下図はDarkNet53のモデルの構造です。
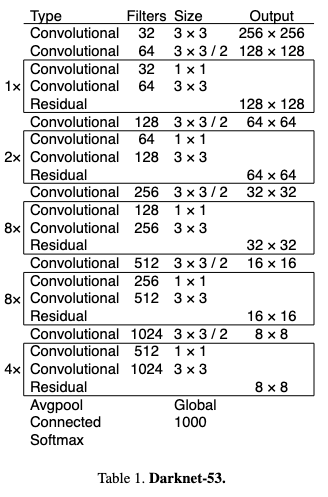
SPP層はDarkNet53の最後のブロック(図.2のx4の部分)のすぐ後に続きます。
SPP層についてですが、下図はYOLOXではなく、SPPを提案した元々の論文から引用した、SPP層の概略図になります。
SPPを提案した元々の論文では、SPP層で用いられるMaxPoolのカーネルサイズは可変であり、様々な解像度の特徴量マップから全結合層に入力するための固定長のベクトルを取得するという意味合いで使われていました。
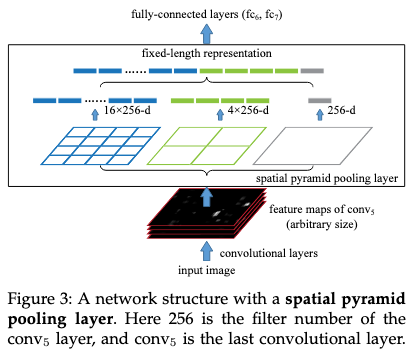
しかし、YOLOv3-SPPでの実装を確認してみたところ、カーネルサイズが固定であり、元々の論文と比較するとSPP層の役割が若干が異なると思われます。YOLOv3-SPPではSPP層を、入力画像の解像度に依存せずに固定長のベクトルを出力するためではなく、単純に受容野の大きさを広げるために使用していると考えています。
# https://github.com/Megvii-BaseDetection/YOLOX/blob/main/yolox/models/network_blocks.py
class SPPBottleneck(nn.Module):
"""Spatial pyramid pooling layer used in YOLOv3-SPP"""
def __init__(
self, in_channels, out_channels, kernel_sizes=(5, 9, 13), activation="silu"
):
super().__init__()
hidden_channels = in_channels // 2
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=activation)
self.m = nn.ModuleList(
[
nn.MaxPool2d(kernel_size=ks, stride=1, padding=ks // 2)
for ks in kernel_sizes
]
)
conv2_channels = hidden_channels * (len(kernel_sizes) + 1)
self.conv2 = BaseConv(conv2_channels, out_channels, 1, stride=1, act=activation)
def forward(self, x):
x = self.conv1(x)
x = torch.cat([x] + [m(x) for m in self.m], dim=1)
x = self.conv2(x)
return x
Decoupled head
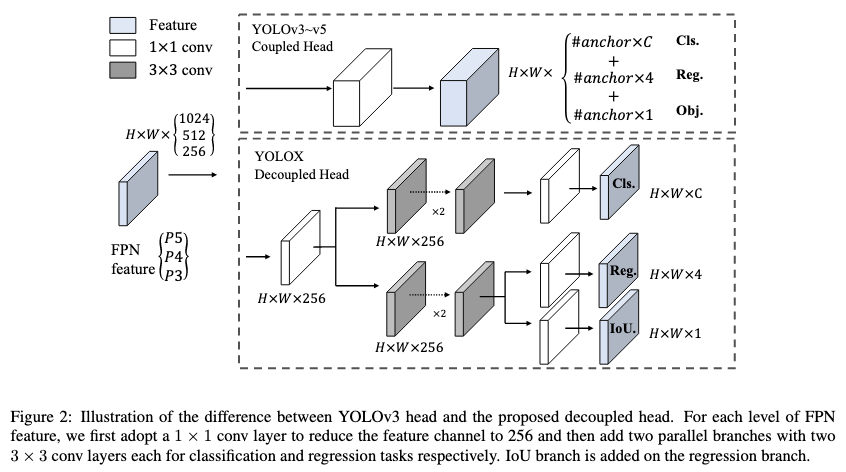
過去のYOLOシリーズでは、下図上部のようにクラス予測、バウンディングボックス回帰予測、オブジェクトスコア予測は全て1つのHeadを通過して出力されていたのですが、YOLOXでは下図下部のようにそれぞれに個別のHeadが割り当てられています。
Strong data augmentation
RandomFlipや、ColorJitterに加えて、MosaicやMixUpといった強力なdata augmentationを適用しています。
Mosaicでは、下図のように4つの画像を混ぜて新たなデータセットを作成します。

MixUpでは、下図のように2つの画像とラベルを特定の割合でブレンドして新たなデータセットを作成します。

Anchor-free
YOLOv2以降のモデルでは、予測ボックスの元となるアンカーボックスを事前に定義していましたが、YOLOXではアンカーボックスを必要としないアンカーフリーなdetection headを採用しています。
アンカーフリーなdetection headを採用することによって、アンカーボックスのハイパーパラメータ(sizeやaspect ratio)を事前に最適化する必要がなくなり、detection headを簡略化することが可能となります。
YOLOv3をアンカーフリーにする方法は非常に簡単で、以下の実装のように、各グリッド点から1つの予測ボックスが生成されるようにし、regression headの4つの出力の最初の2つを各グリッドの左上コーナからのオフセット、残りの2つを幅と高さとして直接利用するだけです。
# https://github.com/Megvii-BaseDetection/YOLOX/blob/main/yolox/models/yolo_head.py
def decode_outputs(self, outputs, dtype):
grids = []
strides = []
for (hsize, wsize), stride in zip(self.hw, self.strides):
yv, xv = torch.meshgrid([torch.arange(hsize), torch.arange(wsize)])
grid = torch.stack((xv, yv), 2).view(1, -1, 2)
grids.append(grid)
shape = grid.shape[:2]
strides.append(torch.full((*shape, 1), stride))
grids = torch.cat(grids, dim=1).type(dtype)
strides = torch.cat(strides, dim=1).type(dtype)
outputs[..., :2] = (outputs[..., :2] + grids) * strides
outputs[..., 2:4] = torch.exp(outputs[..., 2:4]) * strides
return outputs
Multi positives
YOLOv3の正解ボックスと予測ボックスの割り当て規則に従うと、1つの正解ボックスに対して1つのpositive sample(正解ボックスの中心のグリッド点から生成される予測ボックス)しか選択しないため、トレーニング中のpositive sampleとnegative(background) sampleの数が不均一になりがちです。
positive sampleの数が少ないと、有益な勾配が得られにくくなることが知られています。
従って、あるグリッド点について、ある正解ボックスの内側にあり、かつその正解ボックスの中心3×3グリッドである場合、そのグリッド点から生成される予測ボックスはpositiveとし、そのような正解ボックスが存在しない時はnegativeとしています。
SimOTA
トレーニング時に正解ボックスと予測ボックスをどのように割り当てるかは非常に重要な問題です。
比較的よく用いられる方法として、予測ボックスと正解ボックスをIoU(Intersection over Union)が高い順に並べて、順番に割り当てていくという方法があります。
しかし、この方法では複数の正解ボックスが重なっている曖昧な領域でも、予測ボックスに正解ボックスの割り当てを行なってしまい、学習の妨げとなっていました。
OTAでは、正解ボックスと予測ボックスの割り当てを最適輸送問題として定式化し、曖昧な領域での予測ボックスと正解ボックスの割り当てを回避しています。
また、OTAでは、正解ボックスごとに動的に割り当て数を変更するDynamic kという手法も提案しています。
OTAの詳しい解説は以下の記事をご参照ください。
【論文5分まとめ】Ota: Optimal transport assignment for object detection
しかし、OTAを解くSinkhorn-Knoppアルゴリズムは計算量が非常に大きく、25%もの学習時間の増加につながってしまうため、論文ではOTAを簡略化したSimOTAという新しい割り当て方法を提案しています。
SimOTAのアルゴリズムは比較的単純で、まずMulti positive samplingで取得したpositive sampleと正解ボックスのIoUを計算し、OTAと同じくDynamic kで各正解ボックスに割り当てられる予測ボックスの数kを決めた後、各正解ボックスについてコストが小さい予測ボックスから順にk個割り当てを行なっていきます。
1つの予測ボックスについて複数の正解ボックスが割り当てられてしまった場合は、コストが最も小さい正解ボックスを選択し直して割り当てを修正します。
コストの定義式は以下の通りです。
$$
c_{ij} = L^{cls}_{ij} + \lambda L^{reg}_{ij}
$$
$\lambda$はバランス項、$L^{cls}_{ij}$と$L^{reg}_{ij}$はそれぞれ正解ボックスiと予測ボックスjのクラス損失関数とバウディングボックス回帰損失関数です。
比較
上記の各手法を適用した場合のAPスコアの変化は以下の通りです。上記の手法を順番に適用するにつれて、レイテンシの大幅な増加なしに、APスコアが向上していき、最終的にはYOLOv3-ultralyticsという過去のモデルの性能を上回ることに成功しています。
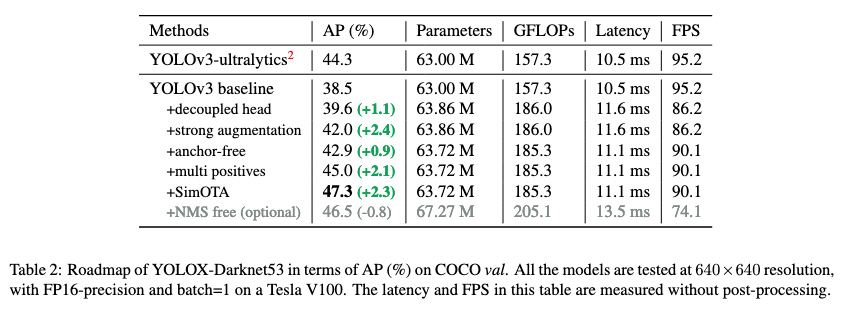
また、その他の過去のリアルタイム物体検出モデルとの性能比較は以下の通りです。
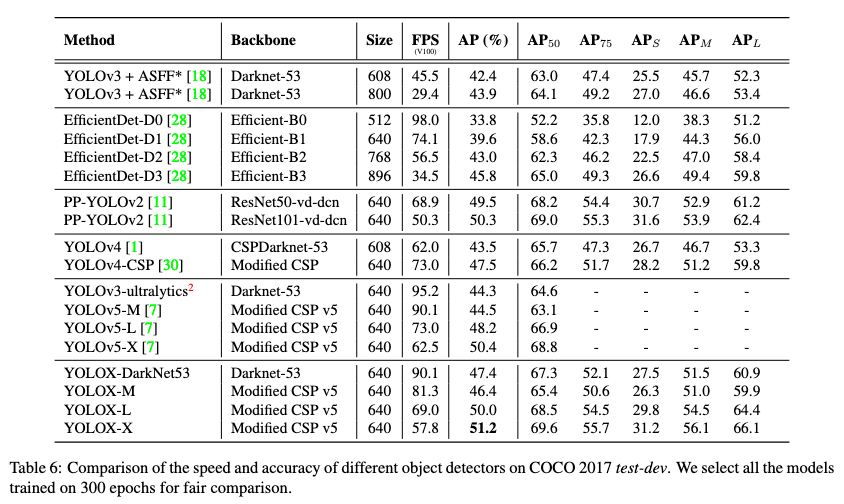
YOLOX-DarkNet53は、YOLOv3をベースラインモデルとして上記の手法を適用したもの、YOLOX-M、-L、-XはYOLOX-DarkNet53のバックボーンを、YOLOv5のバックボーンとネックであるSCPNetとPAN(Path Aggregation Network)に変更したものです。M、L、Xの順番で、ネットワーク全体のサイズが大きくなっています。YOLOX-Xは同程度のリアルタイム性を持つモデルの中で、APの最高値を叩き出しています。
まとめ
今回は、2021年に発表された最新のリアルタイム物体検出モデルであるYOLOXについて紹介いたしました。
Streaming Perception Challengeという物体検出コンペにおいてYOLOXを採用したチームが優勝しており、個人的にはリアルタイム性が重要視されるようなケースでは、しばらくは重宝されるモデルとなるのではないかと考えています。
参考文献
- Zheng Ge, Songtao Liu, Feng Wang, Zeming Li, Jian Sun. YOLOX: Exceeding YOLO Series in 2021 arxiv:2107.08430
- Joseph Redmon, Ali Farhadi. YOLOv3: An Incremental Improvement arxiv:1804.02767
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition arxiv:1406.4729
- Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao. YOLOv4: Optimal Speed and Accuracy of Object Detection arxiv:2004.10934
- Zhi Zhang, Tong He, Hang Zhang, Zhongyue Zhang, Junyuan Xie, Mu Li. Bag of Freebies for Training Object Detection Neural Networks arxiv:1902.04103
- 【論文5分まとめ】Ota: Optimal transport assignment for object detection
- Responding to the Controversy about YOLOv5
